
AI Use Case: Datenvisualisierung mit ChatGPT
In sozialen Netzwerken hört man es immer wieder: Generative AI (GenAI) kann alles! Texte verfassen, Videos drehen, Code schreiben, Bilder erstellen? Alles kein Problem. Keine Frage: Die Möglichkeiten von GenAI sind beeindruckend und schon heute kann man mit ChatGPT & Co viel erreichen. Aber wie einfach ist es, diese Rechenleistung in ein KI-getriebenes Tool zu gießen? Wir machen den Test und entwickeln einen Prototyp eines Datenvisualisierungstools, das Aufforderungen wie „Gib mir ein Liniendiagramm mit den monatlichen Verkaufszahlen des letzten Jahres“ in eine Grafik verwandelt. Ein Erfahrungsbericht.
Der Weg zur einer spracherzeugten Grafik
Kolleg:innen haben hier den Artikel „Jeder kann coden“ veröffentlicht und dort Low-Code/No-Code-Tools thematisiert. In einem ähnlichen Gedanken soll unser Tool es auch Nicht-Programmierern ermöglichen, Grafiken zu unternehmensinternen Daten zu erstellen. Benötigt der CEO „mal eben“ eine Grafik zu den Verkaufszahlen des letzten Jahres, so lässt sich das in Zukunft mit einem Chatfenster und einfacher Anweisung à la „Gib mir ein Liniendiagramm mit den monatlichen Verkaufszahlen des letzten Jahres“ lösen. So jedenfalls das Zukunftsbild.
Überlegen wir uns also, wie wir dort hinkommen möchten. Egal, ob man eine Programmiersprache oder ein No-Code-Tool wie PowerBI nutzt, aktuell sieht es oft so aus, dass im ersten Schritt jemand eine Datenbankabfrage machen muss. Sobald die Daten vorhanden sind, muss die gleiche Person dafür sorgen, dass über ein gewähltes Visualisierungswerkzeug eine Grafik generiert wird. Letztendlich wird in diesem Prozess also eine Person mit technischer Expertise im Programmieren und/oder PowerBI benötigt. Soll die Visualisierung angepasst oder erweitert werden, bedarf es anschließend wieder einer Person, die im Visualisierungstool oder gar auf der Datenbank eingreift.
Glücklicherweise kann ChatGPT auch Code schreiben. Nutzen wir also diese Möglichkeiten und lassen uns für beide Schritte jeweils den richtigen Code erzeugen und miteinander verknüpfen. Am Ende müssten wir diesen Code nur noch auf unseren Computern ausführen, sodass unsere Daten bei uns bleiben. Eine Anweisung an ChatGPT sollte also die folgenden Infos beinhalten:
- Beschreibung der gewünschten Grafik
- Erklärung der Tabellen und Spaltennamen in unserer Datenbank
- Anweisung, Code ohne Erklärungen zu erzeugen (sodass wir den Ausgabetext direkt als unseren auszuführenden Code verwenden können)
Natürlich soll das ein Endnutzer gar nicht alles selbst machen. Wenn unser Tool erstmal steht, dann gibt der User nur die Beschreibung der gewünschten Grafik ein und alle anderen Dinge werden im Hintergrund hinzugefügt und dann an ChatGPT geschickt.
Die Krux an dem ganzen Verfahren ist jedem bekannt, der ChatGPT nutzt: Manchmal passen die generierten Antworten von ChatGPT nur so ungefähr. Das ist verkraftbar bei normalen Texten, wenn ein Mensch ohnehin überprüft, welcher Teil brauchbar ist. Aber bei Code, der automatisiert durchlaufen soll, geht das leider nicht so einfach. Dazu gibt es Lösungen, um den Code durch KI-Agenten so lange anpassen zu lassen, bis keine Fehlermeldungen mehr erscheinen. Um hier aber nicht zu technisch zu werden, verweisen wir technisch versierte Leser:innen gerne an das AutoGen Framework. Widmen wir uns viel lieber den spannenden Fragen.
Eine erste Grafik
Die wichtigste Frage von allen ist vermutlich „Funktioniert unser Ansatz?“ Machen wir den Test und nehmen dazu eine Beispieldatenbank aus dem Internet. Über eine kurze Suche findet man die frei verfügbare Datenbank „Pizza Paradise“ von Observable HQ, die Verkaufszahlen einer fiktiven Kette amerikanischer Pizzerien beinhaltet. Schematisch sieht diese Datenbank so aus wie man es auch oft im echten Leben sieht: Viele Informationen sind verteilt auf einige Tabellen und Spalten.
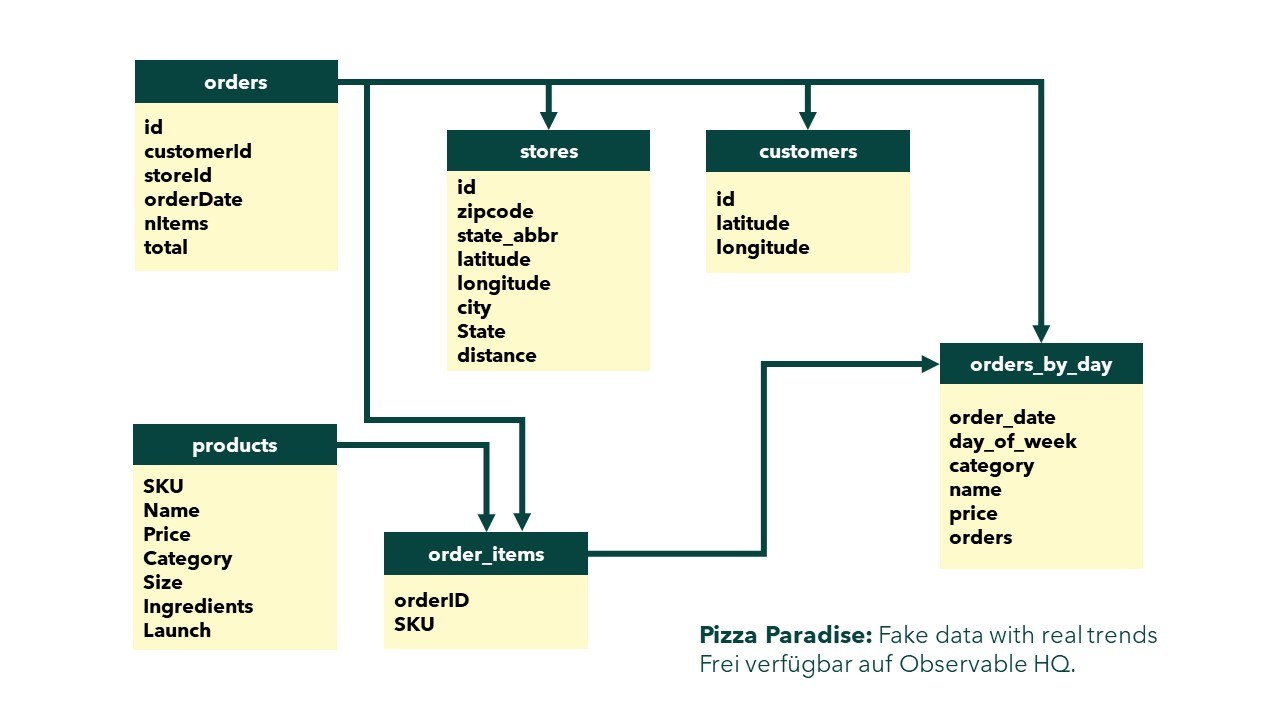
Gewappnet mit dieser Datenbank können wir nun also unsere Strategie testen. Und tatsächlich, erste Grafiken sind möglich:
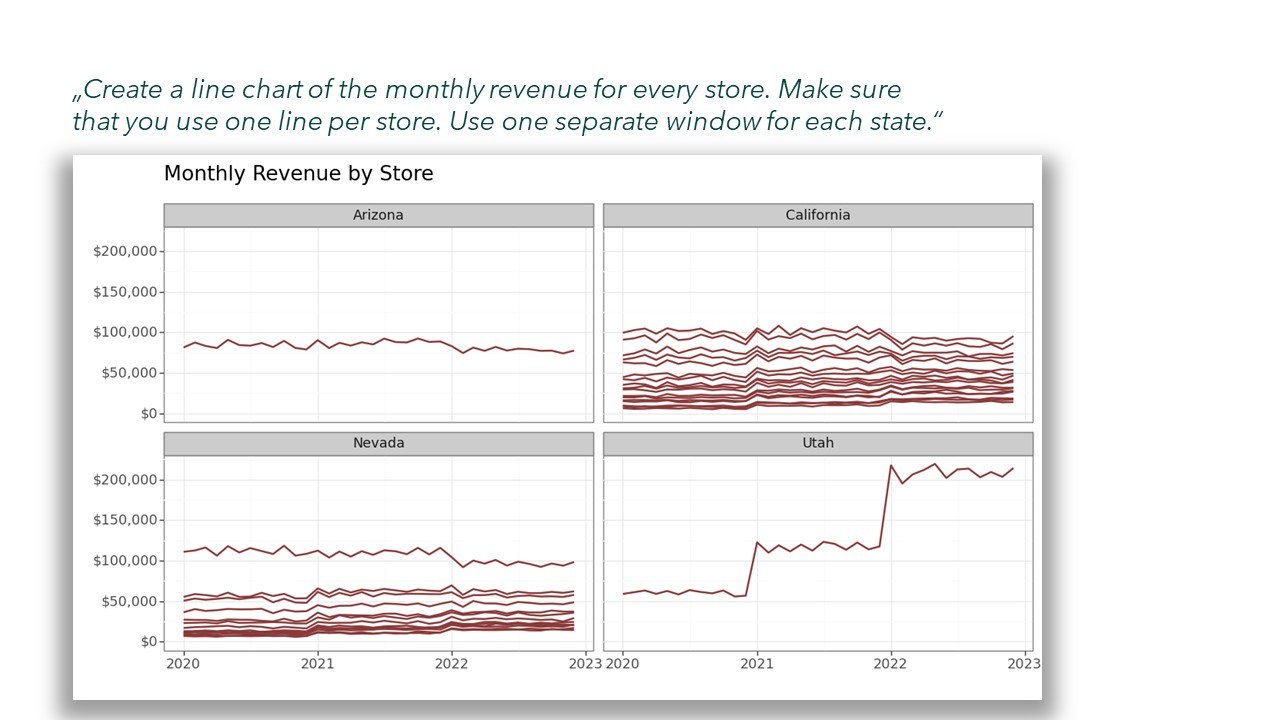
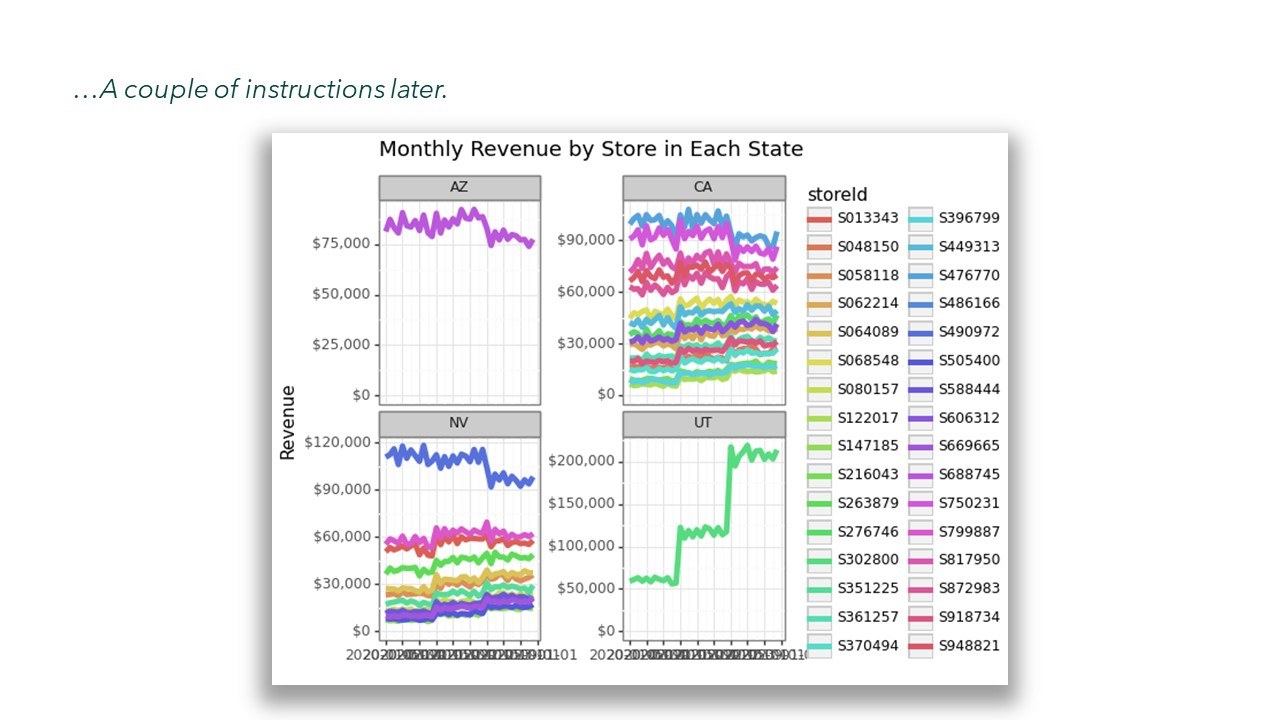
Die Grafik ist nur bedingt eine Schönheit. Es werden unnötig viele Farben verwendet, jedes Fenster hat eine eigene y-Achse und die Beschriftung der x-Achse ist unlesbar, weil die Jahreszahlen überlappen. Aber wie auch im klassischen ChatGPT kann man weitere Anweisungen geben. Wenn man nun also unser Tool Schritt für Schritt anweist, diese Fehler zu beheben, kommt man dem Ziel schon näher:
Learnings
Wie haben hier also im Schnelldurchlauf gesehen, dass man mithilfe von KI und einfachen Strategien schnell einen Prototyp auf die Beine stellen kann. Natürlich ist ein Prototyp kein finales Produkt, aber die Erkenntnisse auf dem Weg dahin sind wichtige Schritte. Dies war auch bei diesem Prototyp nicht anders. Die Erfahrungen auf dem Weg dahin sind vielfältig:
- Fehlerkultur: ChatGPT macht Fehler. Manchmal ist der Code fehlerhaft oder manchmal werden die falschen Daten aus der Datenbank gezogen. Eine automatisierte Lösung wie in diesem Projekt muss sich immer die Frage stellen, wie diese Fehler eingefangen werden und wie man damit umgehen möchte.
- Zufälligkeit: ChatGPT gibt selten zweimal die identische Antwort. Auch in unserem Fall ist das so. Manchmal sind Achsen schön formatiert mit großen Zahlen und den richtigen Trennzeichen, manchmal nicht. Mal sind die Linien blau oder rot. Auch hier muss man sich fallabhängig überlegen, wie man mit dieser Varianz umgehen möchte.
- „Garbage in, garbage out“ gilt immer noch: Wenn man in einer Tabelle unserer Datenbank eine Spalte hat, die Datumsformate JahrMonatTag und TagMonatJahr mischt, kann auch der GenAI-Code Probleme bekommen. Wie beim traditionellen Programmieren kommt es der KI auch auf eine hohe Datenqualität an. Für unseren Use Case haben wir die Dummy-Datenbank erst händisch in ein saubereres Format gebracht.
- Datenschutz: Wenn man sich Texte oder Daten durch eine Blackbox auswerten lassen möchte, steht unweigerlich die Frage im Raum, was da eigentlich im Hintergrund passiert und wie der Datenschutz sichergestellt ist. In unserem Beispiel haben wir unsere Daten weitestgehend von ChatGPT trennen können und mussten „nur“ die Datenbankstruktur oberflächlich beschreiben.
- Rechenzeit/-kosten: Eine spannende wie auch grundsätzliche Frage. Anbieter wie OpenAI kassieren bei jeder Anfrage. Kann sich das ein Unternehmen leisten, wenn jeder Mitarbeiter seine Abfragen an ChatGPT schickt und dann die Resultate auch noch schrittweise optimiert? Das kann sehr schnell sehr teuer werden. Da stellt sich die Frage, ob es sich lohnt, eine „schwächere KI“ in der eigenen Cloud aufzubauen. Hier muss wieder fallabhängig unterschieden werden
- Der menschliche Faktor: Nutzerinnen und Nutzer derartiger KI-Tools müssen in der Lage sein, das Ergebnis zu überprüfen. Hinzu kommt: Je mehr man automatisiert, desto nachvollziehbarer müssen die Ergebnisse sein. Konkret in unserem Fall: Welche Daten hat der generierte Code aus unserer Datenbank gezogen? Handelt es sich tatsächlich, um die Umsatzzahlen von Produkt A oder werden die Zahlen von Produkt B ausgegeben? Hier ist die Balance entscheidend: Wieviel Benefit gebe ich dem User, und was muss er im Gegenzug leisten?
Fazit
Wie so oft ist es beeindruckend, was GenAI alles kann. Die Entwicklung eines sprachbasierten Datenvisualisierungstool wäre wohl ohne KI-Systeme wie ChatGPT unmöglich. Nun ist so ein Tool tatsächlich realisierbar und es ist wohlmöglich nur eine Frage der Zeit, bis sprachgesteuerte Tools in der Reporting-Landschaft ankommen. Aber trotz all der Rechenleistung stellt man schon in der Entwicklung eines Prototypen fest, dass viel zu tun bleibt. Somit bleiben uns auch in einer Zeit von KI komplexe und spannende Fragestellungen erhalten.





